
Multimodal Deep Learning Framework for Dynamic Student Engagement Recognition in Online Education
Keywords:
multi-dimensional, autoencoders, Non-linear features, MFCCs, EEG, LSTM, TransformerAbstract
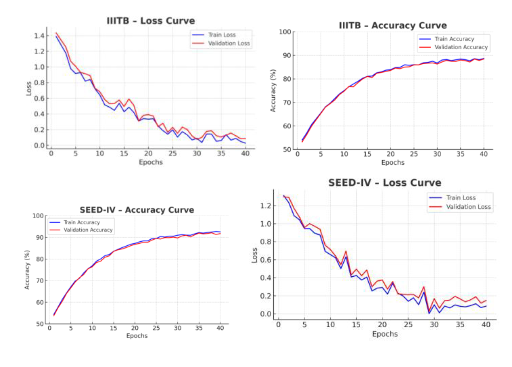
Online education has become a regular practice in today’s education. Student engagement is a key factor that impacts the learning outcomes in online education. However, accurate detection of student’s engagement remains challenging due to its reliance on limited modalities, linear feature representations, and static classification models. Existing vision only methods achieved moderate success but failed to capture the multi-dimensional and dynamic nature of engagement. This study presents a robust framework, that integrates multiple modalities, including visual cues such as facial landmarks, gaze, and expressions, audio features such as MFCCs, prosody, and pauses, and physiological signals such as EEG, where available, and interaction behaviors such as keystrokes and mouse activity. Non-linear feature embeddings are generated using autoencoders to preserve complex dependencies, while temporal deep networks, such as Long Short-Term Memory (LSTM) and Transformers, are employed to capture sequential variations in engagement across time. The proposed model is evaluated on four benchmark datasets, DAiSEE, EmotiW, SEED-IV, and IIITB Online SE and achieves an overall accuracy of 96.8%, precision of 95.7%, recall of 95.4%, and F1-score of 95.5%. Compared to state-of-the-art vision only baselines whose accuracy is only 94%, our approach demonstrates an improvement of 2.5–3%, with notable gains in minority engagement classes. The outcomes substantiates that this approach strengthens robustness, reduces bias, and enhances generalization across various learning environments. This framework establishes a scalable foundation for monitoring real-time engagement in adaptive e-learning platforms, intelligent tutoring systems, and online classroom analytics.
Downloads
Published
Issue
Section
License

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License. You are free to share and adapt the material, but only for non-commercial purposes. You must give appropriate credit to the author(s).


